PyReason
PyReason is a powerful Python-based temporal first-order logic explainable AI system supporting multi-step inference, uncertainty, open-world reasoning, and graph-based syntax.
Read the latest PyReason docs here: https://pyreason.readthedocs.io/en/latest
PyReason Introduction:
• Supports generalized annotated logic with temporal, graphical and uncertainty extensions, capturing a wide variety of fuzzy, real-valued, interval, and temporal logics
• Modern Python-based system supporting reasoning on graph-based data structures (e.g., exported from Neo4j, GraphML, etc.)
• Rule-based reasoning in a manner that support uncertainty, open-world reasoning, non-ground rules, quantification, etc., agnostic to selection of t-norm, etc.
• Fast, highly optimized, correct fixpoint-based deduction allows for explainable AI reasoning, scales to graphs with over 30 million edges

PyReason Paper
https://arxiv.org/pdf/2302.13482.pdf
PyReason Introductory Tutorials
Watch the following introductory videos to learn how to use PyReason with real code examples.
Papers Using PyReason
Geospatial Trajectory Generation via Efficient Abduction: Deployment for Independent Testing (2024)
Preprint: https://arxiv.org/abs/2407.06447
ICLP Talk: https://www.youtube.com/watch?v=8nxuIaTpZzM&ab_channel=NeuroSymbolic
The ability to generate artificial human movement patterns while meeting location and time constraints is an important problem in the security community, particularly as it enables the study of the analog problem of detecting such patterns while maintaining privacy. We frame this problem as an instance of abduction guided by a novel parsimony function represented as an aggregate truth value over an annotated logic program. This approach has the added benefit of affording explainability to an analyst user. By showing that any subset of such a program can provide a lower bound on this parsimony requirement, we are able to abduce movement trajectories efficiently through an informed (i.e., A*) search. We describe how our implementation was enhanced with the application of multiple techniques in order to be scaled and integrated with a cloud-based software stack that included bottom-up rule learning, geolocated knowledge graph retrieval/management, and interfaces with government systems for independently conducted government-run tests for which we provide results. We also report on our own experiments showing that we not only provide exact results but also scale to very large scenarios and provide realistic agent trajectories that can go undetected by machine learning anomaly detectors.
Scalable Semantic Non-Markovian Simulation Proxy for Reinforcement Learning (2024)
Preprint: https://arxiv.org/abs/2310.06835
Code for PyReason-as-a-Sim (integration with DQN): https://github.com/lab-v2/pyreason-rl-sim
Code for PyReason Gym: https://github.com/lab-v2/pyreason-gymlink to paer: https://arxiv.org/abs/2310.06835
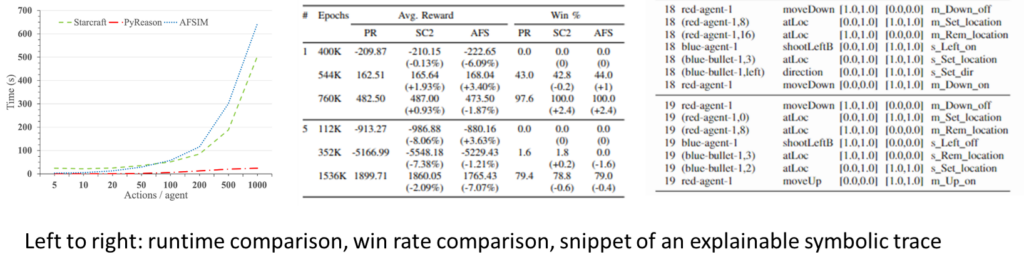
Recent advances in reinforcement learning (RL) have shown much promise across a variety of applications. However, issues such as scalability, explainability, and Markovian assumptions limit its applicability in certain domains. We observe that many of these shortcomings emanate from the simulator as opposed to the RL training algorithms themselves. As such, we propose a semantic proxy for simulation based on a temporal extension to annotated logic. In comparison with two high-fidelity simulators, we show up to three orders of magnitude speed-up while preserving the quality of policy learned. In addition, we show the ability to model and leverage non-Markovian dynamics and instantaneous actions while providing an explainable trace describing the outcomes of the agent actions.
Read the PyReason paper (w. supplement):
https://arxiv.org/pdf/2302.13482.pdf
Introductory blog post:
https://medium.com/towards-nesy/pyreason-software-for-open-world-temporal-logic-d67de751830e
PyReason docs: https://pyreason.readthedocs.io/en/latest
Open source Python library is available at: pypi.org/project/pyreason
PyReason codebase can be found at:
github.com/lab-v2/pyreason
Install with pip:
pip install pyreason
Videos:
Introduction: https://youtu.be/E1PSl3KQCmo
Technical talk: https://youtu.be/G4-jcb2ktKg
Slides:
Introduction to PyReason v 1.1
Bibtex citation:
@inproceedings{aditya_pyreason_2023,
title = {{PyReason}: Software for Open World Temporal Logic},
booktitle = {{AAAI} Spring Symposium},
author = {Aditya, Dyuman and Mukherji, Kaustuv and Balasubramanian, Srikar and Chaudhary, Abhiraj and Shakarian, Paulo},
year = {2023} }
PyReason-as-a-Sim for Deep Reinforcement Learning
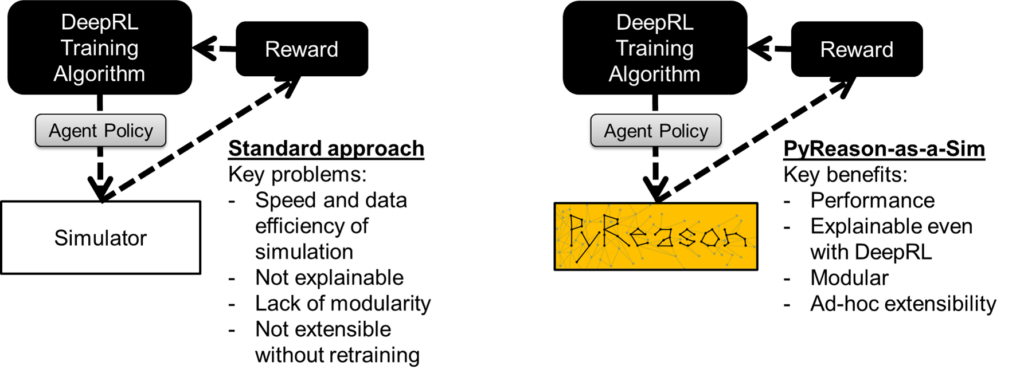
PyReason can function as a semantic proxy for simulation in a reinforcement learning (RL) framework. We showed that inference with PyReason logic program can provide a three order-of-magnitude speedup when compared with native simulations (we studied AFSIM and Starcraft2) while providing comparable reward and win rate (we found that PyReason-trained agents actually performed better than expected in both AFSIM and Starcraft2). However, the benefits of our semantic proxy go well beyond performance. The use of temporal logic programming has two crucial beneficial by-products such as symbolic explainability and modularity. PyReason provides an explainable symbolic trace that captures the evolution of the environment in a precise manner while modularity allows us to add or remove aspects of the logic program – allowing for adjustments to the simulation based on a library of behaviors. PyReason is well-suited to model simulated environments for other reasons – namely the ability to directly capture non-Markovian relationships and the open-world nature (defaults are “uncertain” instead of true or false). We have demonstrated that agents can be trained using standard RL techniques such as DQN using this framework